Mar 09, 2026 • 7 min read
Why Your AI Agents Need Sandboxes (And How Firecracker Makes It Possible)
AI agents are getting more capable by the week. But do you really want an autonomous agent running loose on your machine? Sandboxes are the answer—here's how Firecracker makes it possible.
Why Your AI Agents Need Sandboxes (And How Firecracker Makes It Possible)
AI agents are getting more capable by the week. They can write code, execute shell commands, browse the web, and interact with APIs. But here's the uncomfortable question: do you really want an autonomous agent running loose on your machine with full access to your files, credentials, and network?
You don't.
Sandboxes are the answer. They give each agent its own isolated environment: its own filesystem, its own CPU allocation, its own memory. The agent can do whatever it needs to do inside its sandbox without touching anything outside of it. And because sandboxes are lightweight and disposable, you can spin up dozens of them in parallel, one per agent, one per task, one per customer.
This is the architecture that makes agentic computing safe and scalable. Let's break down how it actually works under the hood.
It Starts With the CPU
To understand sandboxes, you need to understand what you're actually slicing up. Let's start with the CPU.
A modern processor has multiple cores. Each core is an independent processing unit that can execute instructions on its own. Many cores also support simultaneous multithreading (SMT), which Intel brands as Hyper-Threading. This means a single physical core can handle two instruction streams at once by sharing its execution resources between them.
In virtualization, each of these threads maps to one vCPU (virtual CPU). So a processor with 12 cores and SMT enabled gives you 24 threads, which translates to 24 vCPUs that you can distribute across virtual machines.
What Clock Speed Actually Means
You'll see processors advertised with numbers like 2.7 GHz, 3.8 GHz, or 4.7 GHz. This is the clock frequency, and it tells you how many billions of instruction cycles the processor can execute per second.
Higher frequency means each individual core completes work faster. A core running at 4.7 GHz can churn through roughly 74% more cycles per second than one at 2.7 GHz. This matters for single-threaded tasks like compiling code or running a tight loop.
But for sandbox density, frequency is less important than core count. You'd rather have 24 cores at 2.4 GHz than 8 cores at 5.0 GHz, because you're trying to run many lightweight workloads in parallel rather than one heavy workload fast.
Overcommitting: Why 24 vCPUs Can Serve 100 Sandboxes
Here's where it gets interesting. If a 24-thread machine can only provide 24 vCPUs, that limits you to 24 sandboxes, right?
Not in practice.
Most VM and sandbox workloads don't demand continuous CPU activity. The processor spends most of its time idle, waiting for something: a network response, a disk read, user input. This is why cloud providers offer two kinds of instances:
Dedicated instances lock a specific vCPU to your workload. Nobody else can use it, even when you're not. You pay a premium for this guarantee.
Shared instances allow the provider to assign the same physical CPU resources to multiple customers. When your workload is idle, someone else's workload can use those cycles. This is called overcommitting, and providers typically use ratios of 4:1 or 8:1 depending on the workload profile.
For AI agent sandboxes, you can push this even further. Agentic workloads are fundamentally I/O bound, not CPU bound. The typical lifecycle of an agent task looks like this:
- Agent receives instruction
- Agent calls an LLM API (waits 2-30 seconds for response)
- Agent processes the response (brief CPU spike)
- Agent executes a command or writes a file (brief I/O)
- Agent calls the LLM again (waits again)
The CPU is active for maybe 5-10% of the total execution time. The rest is spent waiting on network calls. This means while one sandbox is waiting for an API response, dozens of others can take turns using the same physical CPU.
With conservative 4:1 overcommit, a 24-thread machine can serve 96 sandboxes. At 8:1, that's 192. The real constraint becomes RAM, not CPU, because each sandbox needs a minimum memory allocation whether it's actively computing or not.
Enter Firecracker
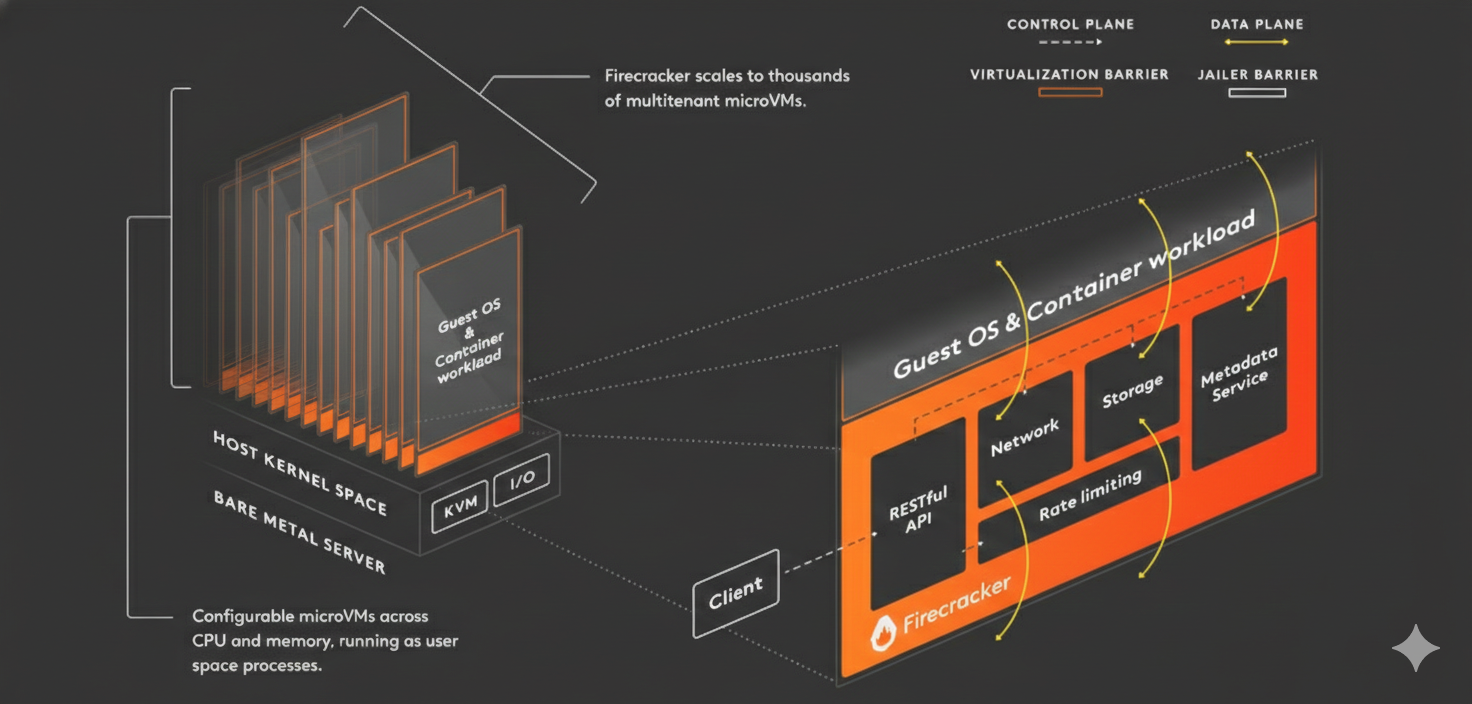
This is where Firecracker comes in.
Firecracker is an open source virtual machine monitor (VMM) built by AWS. It's the technology that powers Lambda and Fargate under the hood. It was purpose-built for one thing: spinning up lightweight, secure virtual machines as fast as possible.
Traditional hypervisors like QEMU are powerful but heavy. They emulate entire hardware platforms, complete with virtual BIOS, USB controllers, and PCI buses. A QEMU VM can take seconds to boot and consumes hundreds of megabytes of overhead.
Firecracker takes a radically minimal approach. It emulates only what's absolutely necessary: a small number of virtio devices for disk, network, and a serial console. Nothing else. No graphics, no USB, no legacy hardware emulation. The result:
- Boot time: Under 125 milliseconds to a working Linux kernel
- Memory overhead: Approximately 5 MB per microVM for the VMM process itself
- Security: Each microVM runs in its own KVM-backed hardware-isolated boundary, providing the same level of isolation as traditional VMs
How Firecracker Partitions Resources
Firecracker uses the Linux KVM (Kernel-based Virtual Machine) interface to create hardware-isolated virtual machines. When you launch a Firecracker microVM, you specify exactly what it gets:
CPU: You assign a specific number of vCPUs. Firecracker pins these to the host's threads, but because the guest OS yields the CPU whenever it's idle, the hypervisor can schedule other microVMs on the same physical threads. This is what makes overcommitting work transparently.
Memory: You specify an exact amount of RAM in megabytes. The memory is allocated from the host and isolated per VM. One sandbox cannot access another's memory space because it's enforced at the hardware level by KVM.
Storage: Firecracker attaches block devices (typically disk images) as virtio-blk devices. Each sandbox gets its own root filesystem. These can be minimal Linux images, sometimes as small as 50 MB, containing just the tools the agent needs: a shell, Python or Node.js, git, and the agent runtime.
Network: Each microVM gets a TAP device for networking, which can be bridged to the host network or isolated in its own network namespace.
The beauty is that all of this happens through a simple REST API. You POST a JSON configuration, and Firecracker returns a running VM in milliseconds. No XML configuration files, no complex setup ceremonies.
The Orchestration Layer
Firecracker handles the low-level virtualization, but a production sandbox platform needs more. You need an orchestration layer that manages the full lifecycle:
Pool management: Pre-warming a pool of microVMs so that when a request comes in, a sandbox is ready instantly instead of booting from scratch.
Snapshot and restore: Firecracker supports snapshotting a running microVM's full state (memory, CPU registers, device state) to disk and restoring it later. This enables features like pause/resume and fast cloning. Instead of booting a fresh VM and installing dependencies, you snapshot a fully configured environment and restore copies of it in microseconds.
Resource limits: Setting CPU and memory cgroups so that a runaway process inside one sandbox can't starve others on the same host.
API exposure: Providing a clean API that upstream applications and services can call to create, connect to, execute commands in, and destroy sandboxes. This is the interface that your agent framework, your CI/CD system, or your development platform actually talks to.
Networking: Setting up network isolation so sandboxes can reach the internet (for API calls and package installs) but cannot reach each other or the host's internal services.
How We Built Mags
This is exactly the architecture behind Mags.
We built Mags to provide sandboxed execution environments for AI agents, running Firecracker microVMs on bare metal machines. Not cloud VMs running VMs (nested virtualization), but direct-to-metal Firecracker instances for maximum performance and density.
Each sandbox is a full Linux environment with its own CPU, memory, filesystem, and network, isolated at the hardware level. Agents can install packages, write files, run servers, execute arbitrary code, all without any risk of escaping the sandbox or affecting other tenants.
The result is a platform where you can spin up a secure, isolated compute environment for your agent in milliseconds, use it for as long as you need, and tear it down when you're done. No configuration, no cleanup, no security concerns.
Because at the end of the day, the question isn't whether your agents should be sandboxed. It's whether you can afford for them not to be.
Mags provides sandboxed execution environments for AI agents. Built on Firecracker microVMs running on bare metal infrastructure.